S-LoRA: Több ezer LLM futtatása egy GPU-n
Az S-LoRA innovatív technikája új mércét állít fel az AI területén és példátlan GPU-kihasználást tesz lehetővé, amellyel több ezer LLM futtatása lehetséges egyetlen GPU-n.

-
A Stanford és a UC Berkeley kutatói által kifejlesztett S-LoRA jelentősen csökkenti a nagy nyelvi modellek finomhangolásának költségeit és számítási igényeit.
-
Ez az innovatív technika lehetővé teszi több száz vagy több ezer LLM futtatását egyetlen GPU-n, leküzdve a memória és a számítási erőforrások korábbi korlátait.
Ha többet akarsz tudni, kövess minket Facebookon! -
Az S-LoRA dinamikus memóriakezelése és tenzor-párhuzamossági rendszerei lehetővé teszik több modell hatékony kezelését, ami a különböző iparágak AI-alkalmazásai számára változást hozhat.
A nagy nyelvi modellek (LLM) finomhangolása hagyományosan erőforrás-igényes folyamat, ami gyakran korlátozza a hozzáférhetőségét a jelentős számítási képességekkel rendelkező szervezetek számára. A Stanford Egyetem és a UC Berkeley kutatóinak közös innovációja, az S-LoRA megjelenése azonban megváltoztatja ezt a helyzetet. Az S-LoRA drámaian csökkenti a finomhangolt LLM-ek telepítésével járó számítási és pénzügyi terheket, lehetővé téve több száz vagy akár több ezer modell működtetését egyetlen grafikus feldolgozó egységen (GPU).
Az LLM-ek finomhangolásának hagyományos módszere magában foglalja az előre betanított modell új adatokkal való átképzését, amely számos paraméter beállítását és jelentős számítási erőforrások igénybevételét jelenti. Az S-LoRA azonban egy Low-Rank Adaptation-nek (LoRA) nevezett technikát használ, amely azonosítja és finomhangolja a paraméterek minimális részhalmazát. Ez a megközelítés nemcsak a pontosságot tartja fenn, hanem drasztikusan csökkenti a betanítható paraméterek számát is, ezáltal csökkentve a memória- és a számítási igényt.
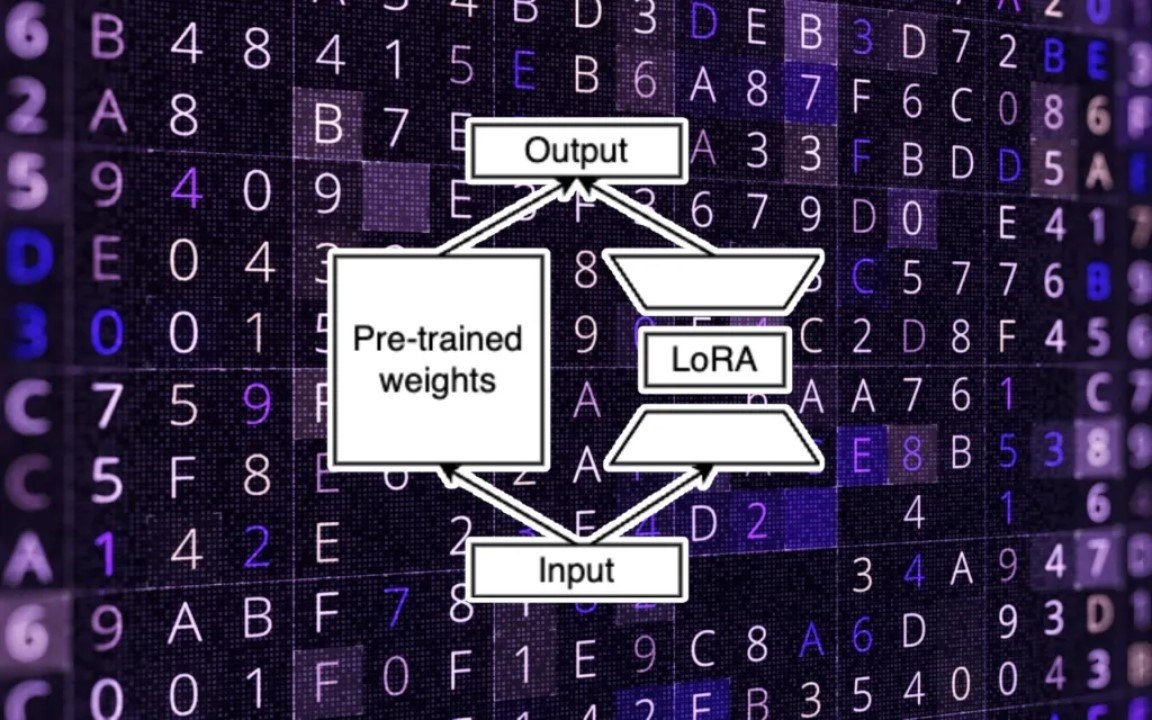
Az S-LoRA hatékonyságát tovább növeli a dinamikus memóriakezelő rendszer, amely zökkenőmentesen továbbítja a LoRA elemeit a főmemória és a GPU között. Ez a rendszer az „Unified Paging” mechanizmussal párosulva még több száz kötegelt lekérdezés kezelése esetén is zökkenőmentes működést biztosít. Az S-LoRA emellett egy újszerű „tensor-párhuzamossági” rendszert is tartalmaz, így kompatibilis a több GPU-n futó nagy transzformátor modellekkel. Ezek az újítások lehetővé teszik, hogy az S-LoRA számos LoRA-adaptert szolgáljon ki egyetlen GPU-n vagy több GPU-n, legyőzve a memóriakezelés és a kötegelt folyamatok korábbi technikai kihívásait.
Az S-LoRA gyakorlati alkalmazásai széles körűek és változatosak. A tartalomkészítéstől az ügyfélszolgálatig a vállalkozások mostantól a finomhangolt LLM-eket kihasználva személyre szabott szolgáltatásokat nyújthatnak a szokásos költségek töredékéért. Egy blogplatform például az S-LoRA segítségével olyan finomhangolt LLM-eket kínálhat, amelyek képesek utánozni az egyes szerzők írói stílusát, mindezt minimális költségek mellett. A GitHub-on elérhető S-LoRA kódja készen áll arra, hogy a népszerű LLM-kiszolgáló keretrendszerekbe integrálható legyen, ami jelentős előrelépést jelent a hatékony AI-feldolgozás elérhetővé tételében a vállalatok és alkalmazások szélesebb köre számára.
- Legfrissebb
- Nem a technológia hiányzik, hanem a szokás: az Eurostat szerint az európaiak többsége nem érzi szükségesnek az AI-eszközöket
- A Google törölte a Disney-szereplős AI-videókat a YouTube-ról, miután felszólító levelet kapott
- Codex Mortis: ez a videójáték már teljes egészében mesterséges intelligenciával készült, ki is próbálhatod
- GPT-5.2 bemutató: az OpenAI új csúcsmodellje már nem csak válaszol, hanem munkatársként működik
- Hogyan növekednek gyorsabban a vállalkozások az AI-alapú digitális marketingplatformokkal?
- Meglepő igazság: több milliárdos interakció elemzéséből derült ki, hogyan is használjuk a mesterséges intelligenciát
- Az AI-tagadás mint vállalati kockázat: tényleg csak digitális moslékot csinál a mesterséges intelligencia?
- Ez lesz az OpenAI új gyónási rendszere: amikor a modell maga vallja be, ha hibázott
- A chatbotok sokkal hatékonyabban formálják a politikai véleményt, mint a tévés kampányhirdetések
- Áttörés a mellrákszűrésben? A DeepHealth új platformja már most átírja a radiológia jövőjét
- Képernyőidő
- Már nem elég megnézni a Harry Pottert: podcastokkal bővül az HBO Max Magyarországon is
- Kevesebb kattintás, több Gemini - öt dolog, amiből jól látszik, milyen jövőt tervez nekünk a Google
- Most te is megnézheted, mi volt a legelső zeneszám, amit meghallgattál Spotify-on
- A Sony drámai döntése: tényleg vége lehet a nagy PlayStation-játékok PC-s korszakának
- Birkakrimi - kritika szülői szemmel egy puha gyapjúba csomagolt gyilkossági történetről
- Legnépszerűbb címkék
- OpenAI
- ChatGPT
- generatív AI
- AI
- Microsoft
- innováció
- NVIDIA
- GPT-4
- technológia