Arthur Bench: Egy hatékony nyílt forráskódú eszköz az AI-modellek értékeléséhez
Az Arthur, egy AI startup, bemutatta az Arthur Bench-et, egy nyílt forráskódú eszközt, amely a nagy nyelvi modellek átfogó értékelését és összehasonlítását teszi lehetővé a vállalkozások számára.
-
Az Arthur, egy AI startup, elindítja az Arthur Bench-et, egy nyílt forráskódú eszközt a nagy nyelvi modellek értékelésére.
-
Az Arthur Bench mérőszámokat biztosít a modellek pontosság, olvashatóság és más kritériumok alapján történő összehasonlításához, olyan kérdésekkel foglalkozva, mint az „elfedés”.
Ha többet akarsz tudni, kövess minket Facebookon! -
Az eszköz adaptálható, lehetővé téve a vállalatok számára, hogy saját kritériumokat adjanak hozzá, és már több iparág is alkalmazza.
Az Arthur, egy New York-i székhelyű AI startup bejelentette, hogy elindította az Arthur Bench-et, egy nyílt forráskódú eszközt a nagy nyelvi modellek (LLM), például az OpenAI GPT-3.5 Turbo és a Meta LLaMA 2 teljesítményének értékelésére és összehasonlítására. „A Bench segítségével egy nyílt forráskódú eszközt hoztunk létre, amely segít a csapatoknak alaposan megérteni az LLM-szolgáltatók közötti különbségeket, a különböző felszólítási és kiegészítési stratégiákat, valamint az egyéni képzési rendszereket” – mondta Adam Wenchel, az Arthur vezérigazgatója és társalapítója sajtóközleményében.
Az Arthur Bench lehetővé teszi a vállalatok számára, hogy teszteljék a különböző nyelvi modellek teljesítményét a saját konkrét felhasználási eseteiken. Mérőszámokat biztosít a modellek összehasonlításához a pontosság, az olvashatóság, az elfedés és más kritériumok alapján. Azok számára, akik már többször használtak LLM-eket, az „elfedés” különösen feltűnő probléma – ez az, amikor egy LLM olyan idegen nyelvi kifejezéseket ad meg, amelyek összefoglalják vagy utalnak a szolgáltatás feltételeire vagy a programozási korlátozásokra, például azt mondják, hogy „AI nyelvi modellként...”, ami általában nem lényeges a felhasználó által kívánt válasz szempontjából.
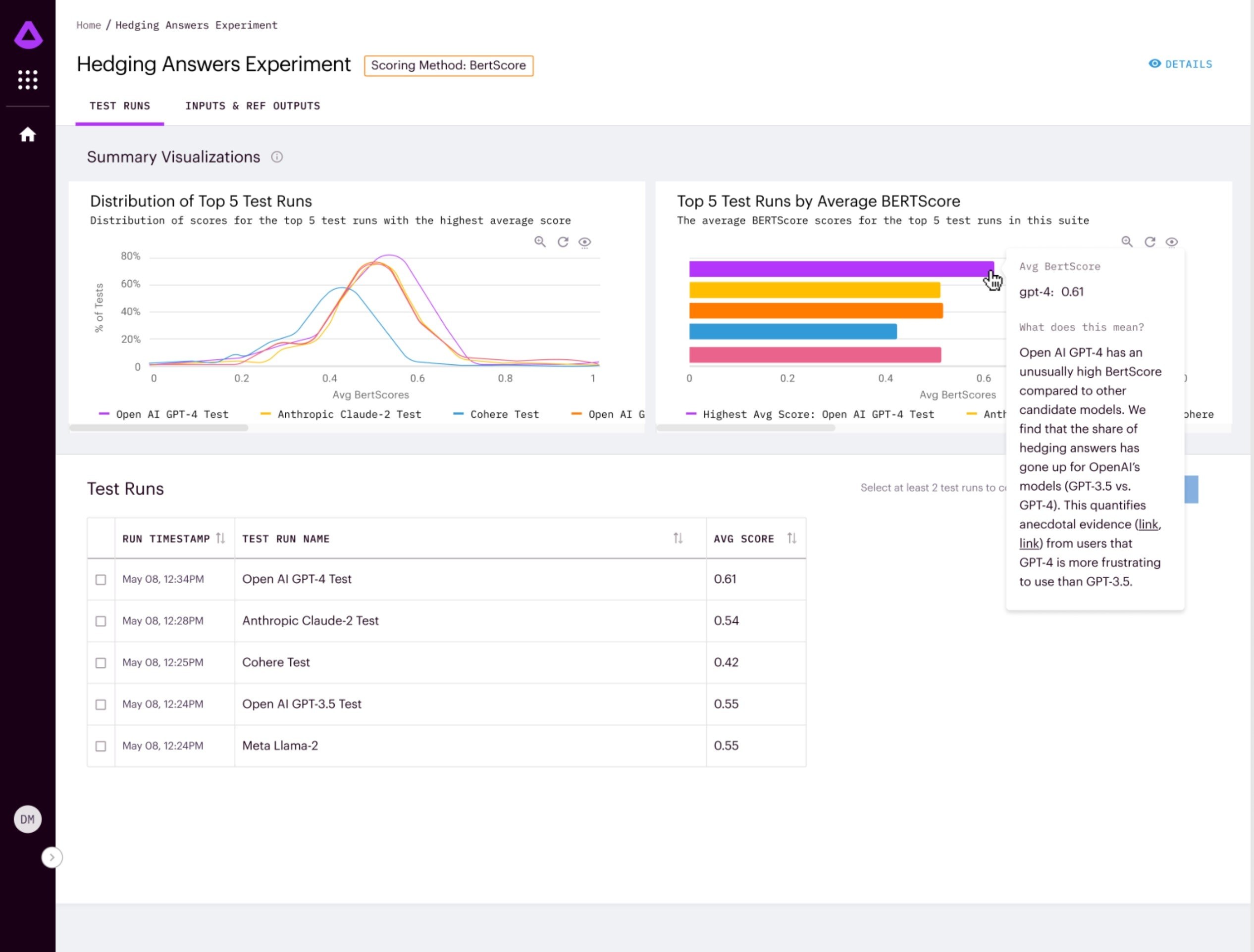
Arthur számos olyan induló kritériumot tartalmaz, amelyek alapján az LLM teljesítményét össze lehet hasonlítani, de mivel az eszköz nyílt forráskódú, az azt használó vállalkozások saját igényeiknek megfelelően saját kritériumokat is hozzáadhatnak. „Foghatjuk a felhasználók által feltett utolsó 100 kérdést és lefuttathatjuk őket az összes modellen. Ezután az Arthur Bench kiemeli azokat a helyeket, ahol a válaszok nagymértékben eltérnek egymástól, így ezeket manuálisan felülvizsgálhatjuk” – magyarázta Adam Wenchel, hozzátéve, hogy a cél az, hogy a vállalkozások megalapozott döntéseket hozhassanak a mesterséges intelligencia bevezetésekor. Az Arthur Bench felgyorsítja a teljesítményértékelést és a tudományos méréseket valós üzleti hatásokká alakítja át. A vállalat statisztikai mérések és pontszámok kombinációját, valamint más LLM-ek értékelését használja, hogy a kívánt LLM-ek válaszát egymás mellett osztályozza.
Az Arthur Bench-et már most is használják a pénzügyi szolgáltató cégek, hogy gyorsabban készítsenek befektetési téziseket és elemzéseket. A járműgyártók fogták a sokoldalas, rendkívül specifikus műszaki útmutatókat tartalmazó felszerelési kézikönyveiket és az Arthur Bench segítségével olyan LLM-eket hoztak létre, amelyek képesek az ügyfelek kérdéseire válaszolni, miközben gyorsan és pontosan keresik az információkat az említett kézikönyvekből, miközben csökkentik a hallucinációkat. Egy másik ügyfél, az Axios HQ vállalati média- és kiadói platform szintén az Arthur Benchet használja a termékfejlesztési oldalán. Az Arthur Bench elérhető a Github oldaláról.
- Legfrissebb
- Nem a technológia hiányzik, hanem a szokás: az Eurostat szerint az európaiak többsége nem érzi szükségesnek az AI-eszközöket
- A Google törölte a Disney-szereplős AI-videókat a YouTube-ról, miután felszólító levelet kapott
- Codex Mortis: ez a videójáték már teljes egészében mesterséges intelligenciával készült, ki is próbálhatod
- GPT-5.2 bemutató: az OpenAI új csúcsmodellje már nem csak válaszol, hanem munkatársként működik
- Hogyan növekednek gyorsabban a vállalkozások az AI-alapú digitális marketingplatformokkal?
- Meglepő igazság: több milliárdos interakció elemzéséből derült ki, hogyan is használjuk a mesterséges intelligenciát
- Az AI-tagadás mint vállalati kockázat: tényleg csak digitális moslékot csinál a mesterséges intelligencia?
- Ez lesz az OpenAI új gyónási rendszere: amikor a modell maga vallja be, ha hibázott
- A chatbotok sokkal hatékonyabban formálják a politikai véleményt, mint a tévés kampányhirdetések
- Áttörés a mellrákszűrésben? A DeepHealth új platformja már most átírja a radiológia jövőjét
- Képernyőidő
- Már nem elég megnézni a Harry Pottert: podcastokkal bővül az HBO Max Magyarországon is
- Kevesebb kattintás, több Gemini - öt dolog, amiből jól látszik, milyen jövőt tervez nekünk a Google
- Most te is megnézheted, mi volt a legelső zeneszám, amit meghallgattál Spotify-on
- A Sony drámai döntése: tényleg vége lehet a nagy PlayStation-játékok PC-s korszakának
- Birkakrimi - kritika szülői szemmel egy puha gyapjúba csomagolt gyilkossági történetről
- Legnépszerűbb címkék
- OpenAI
- ChatGPT
- generatív AI
- AI
- Microsoft
- innováció
- NVIDIA
- GPT-4
- technológia