A Meta bemutatja az I-JEPA-t: Egy forradalmi képalapú gépi tanulási modell
A Meta bemutatta az I-JEPA nevű újszerű gépi tanulási modellt, amelyet arra terveztek, hogy ön-felügyelt tanulással komplex fogalmakat ragadjon meg képekből, megnyitva ezzel az utat a hatékonyabb AI-rendszerek felé.

A Meta jelentős lépést tett Yann LeCun víziójának megvalósítása felé, olyan mély tanulási rendszerekről, amelyek képesek megtanulni a világmodelleket az emberi segítség nélkül, az I-JEPA nevű innovatív gépi tanulási modelljének bemutatásával. Ez a modell ön-felügyelt tanulást alkalmaz a világ absztrakt kifejeződéseinek megragadására, elsősorban képelemzéssel. Az első értékelések szerint az I-JEPA kiváló teljesítményt nyújt különböző számítógépes látási feladatokban és hatékonyságban, felülmúlja a többi csúcsmodellt azzal, hogy a számítási erőforrások csak töredékét használja fel a képzéshez. A képzési kódot és modellt a Meta nyílt forráskóddal bocsátotta rendelkezésre, és a közelgő Conference on Computer Vision and Pattern Recognition (CVPR) konferencián mutatják be.
Az ön-felügyelt tanulás az emberek és állatok megfigyelésen keresztül történő tanulására építve olyan paradigmát kínál, amelyben a mesterséges intelligencia rendszerek a nyers adatokon keresztül gyűjthetnek tudást, így nincs szükség az ember által biztosított képzési adatok címkézésére. Ez a megközelítés forradalmasította a mesterséges intelligencia egyes területeit, különösen a nagy nyelvi modelleket és a generatív modelleket. 2022-ben Yann LeCun bemutatta a "közös prediktív beágyazási architektúrát" (JEPA), egy egyedülálló ön-felügyelt modellt, amely a hagyományos ön-felügyelt modellektől eltérően tanul meg magas szintű absztrakciókat és fontos információkat, például a józan észt.

Az olyan generatív modellekkel ellentétben, mint a DALL-E és a GPT, amelyek a részletes előrejelzésekre összpontosítanak, a JEPA célja az átfogó absztrakciók, például a jelenet tartalmának és az objektumok közötti kapcsolatok megértése és előrejelzése. Ez a megközelítés kevesebb hibát, alacsonyabb számítási költségeket és a környezet rejtett terének mélyebb megértését eredményezi. A Meta kutatói úgy vélik, hogy a pixelértékek helyett a magas szintű absztrakciók közvetlen előrejelzése megkerüli a generatív megközelítésekben rejlő korlátokat.
Az I-JEPA a Yann LeCun által javasolt struktúra képközpontú megvalósítása. A hiányzó információt absztrakt előrejelzési célok segítségével különbözteti meg, kiküszöbölve a felesleges pixel-szintű részleteket, és jelentéstanilag gazdagabb jellemzőtanuláshoz vezet. Az I-JEPA egy látástranszformátort (ViT) használ az információ kódolására, amelyet aztán egy prediktív ViT-hez továbbít, hogy jelentéstani reprezentációkat hozzon létre a hiányzó részekre. A gyakorlatban ez jelentős előrelépést jelenthet olyan ágazatokban, mint a robotika és az autonóm járművek, ahol a mesterséges intelligenciának meg kell értenie a környezetét, és több lehetséges eredményt is kell kezelnie.
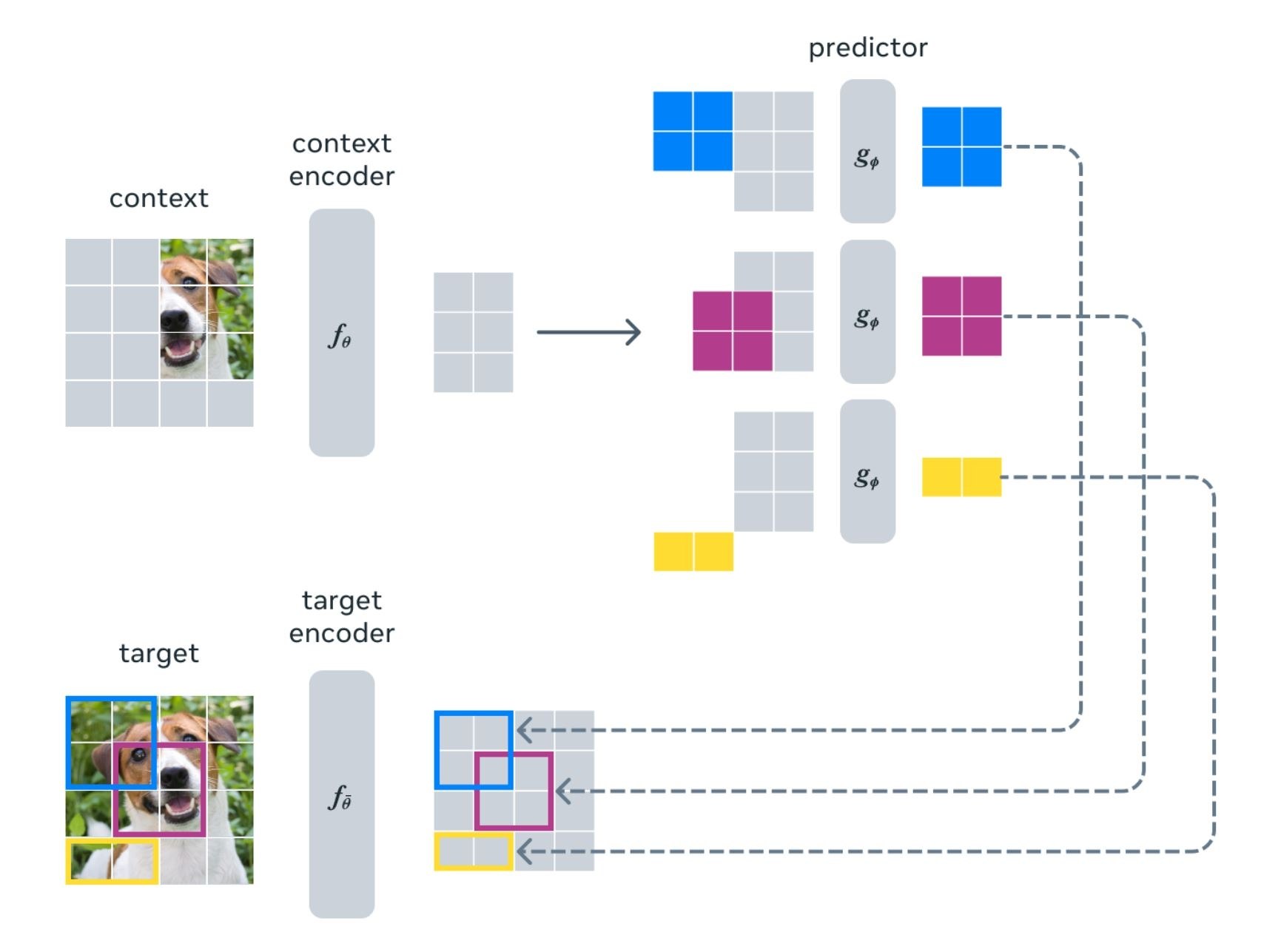
A kiváló teljesítmény mellett az I-JEPA a hatékonyság terén is kiemelkedik, mivel lényegesen kevesebb memóriát és számítást igényel. Az előtanulmányozási fázis nélkülözi a más ön-felügyelt tanulási módszerekre jellemző erőforrás-igényes adatnövelési technikákat. A modell sokkal kevesebb finomhangolást igényel ahhoz, hogy felülmúlja a többi csúcskategóriás modellt az olyan számítógépes látási feladatokban, mint az osztályozás, az objektumszámlálás és a mélységbecslés. A bőséges címkézetlen internetes adatok korában az I-JEPA-hoz hasonló modellek kulcsfontosságúak lehetnek olyan alkalmazások számára, amelyekhez korábban hatalmas mennyiségű kézzel címkézett adatra volt szükség.
- Legfrissebb
- Nem a technológia hiányzik, hanem a szokás: az Eurostat szerint az európaiak többsége nem érzi szükségesnek az AI-eszközöket
- A Google törölte a Disney-szereplős AI-videókat a YouTube-ról, miután felszólító levelet kapott
- Codex Mortis: ez a videójáték már teljes egészében mesterséges intelligenciával készült, ki is próbálhatod
- GPT-5.2 bemutató: az OpenAI új csúcsmodellje már nem csak válaszol, hanem munkatársként működik
- Hogyan növekednek gyorsabban a vállalkozások az AI-alapú digitális marketingplatformokkal?
- Meglepő igazság: több milliárdos interakció elemzéséből derült ki, hogyan is használjuk a mesterséges intelligenciát
- Az AI-tagadás mint vállalati kockázat: tényleg csak digitális moslékot csinál a mesterséges intelligencia?
- Ez lesz az OpenAI új gyónási rendszere: amikor a modell maga vallja be, ha hibázott
- A chatbotok sokkal hatékonyabban formálják a politikai véleményt, mint a tévés kampányhirdetések
- Áttörés a mellrákszűrésben? A DeepHealth új platformja már most átírja a radiológia jövőjét
- Képernyőidő
- Már nem elég megnézni a Harry Pottert: podcastokkal bővül az HBO Max Magyarországon is
- Kevesebb kattintás, több Gemini - öt dolog, amiből jól látszik, milyen jövőt tervez nekünk a Google
- Most te is megnézheted, mi volt a legelső zeneszám, amit meghallgattál Spotify-on
- A Sony drámai döntése: tényleg vége lehet a nagy PlayStation-játékok PC-s korszakának
- Birkakrimi - kritika szülői szemmel egy puha gyapjúba csomagolt gyilkossági történetről
- Legnépszerűbb címkék
- OpenAI
- ChatGPT
- generatív AI
- AI
- Microsoft
- innováció
- NVIDIA
- GPT-4
- technológia